
Wednesday, May 6, 2015
Tuesday, May 5, 2015
Statistics
Now I have some data to show and I made some cool graphs. First, I would like to explain the meaning of the terms "Round" and "Try" in my statistics. When someone plays Pacman and die 3 times, it is one round, and his/her first try. If he/she keep playing, without closing the game, it is going to be the second try, and in that way go on. Second, I ran the QLearning Pacman for 4600 rounds, the Random Pacman for 2000 rounds, and 4 different humans played two rounds each. It is a pretty small number of human players, but we can have some general view from that anyway. Lets go to the graphs:
So, when we are playing against each other, the most common question is "What is your high-score?" than, I decided to compare it, and the result was pretty impressive. The Qlearning algorithm achieved a score almost two times higher than the humans.




So, when we are playing against each other, the most common question is "What is your high-score?" than, I decided to compare it, and the result was pretty impressive. The Qlearning algorithm achieved a score almost two times higher than the humans.
Someone could say: "Okay, but I am sure that humans gonna have a better average!", but the data shows the opposite. Even with a smaller difference, the Qlearning algorithm still showing a better score.
At first, I thought that I could see the evolution of the Pacman through his tries, so I build that graph bellow that shows the average of scores through his tries. Otherwise, the results showed that the learning of the algorithm is so fast, that it is not really visible through tries, because it happen just in the first moment of each experience. In this chart I decided to use a average of all human scores to be seen as a reference of performance.
QLearning Pacman is better than humans?
I wouldn't say that, besides the fact that we have a really small population of human rounds, the way that I designed the game can influence in the final result of that data. I designed the game to increase the difficulty exponentially through the levels intended in make the game quick, interesting and challenger. As we can see in the graph bellow, the humans has a tendency to try go on through levels faster that the QL Pacman. It happens because I gave a high reward to the QL Pacman when he ate ghosts, so he decided to give priority to that instead of only go to the next level. Otherwise, it doesn't mean that the humans use a bad strategy, the key point here is that the level 2 (which is the third) is really hard and no one could get through it.
Q-Learning Pacman
The main goal of the project is to apply the QLeaning algorithm in the Pacman, so I am going to explain how that algorithm works.
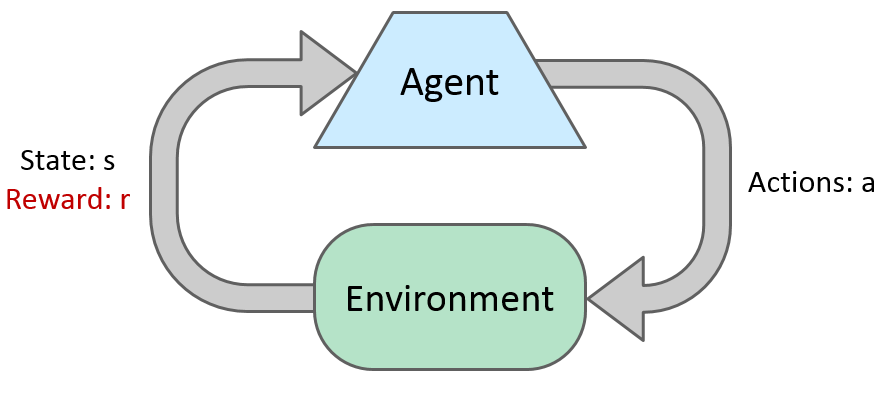
Basic Idea
Most algorithms of reinforcement learning follow the model of a MDP, but not knowing T or R.
Markov Decision Process
A set of states s in S
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
Monday, May 4, 2015
Features and Rewards
The features and the rewards are the soul of the QLearning algorithm and of the Pacman agent. Nonetheless, it is the hardest part to get right and, even with high scores, I still thinking the best way to do. I implemented up to 10 different features to represent a state, and tried a lot of combinations between then, but I could do it for more one month until discover the best way, because it is really fun to see the variations in the Pacman behavior according with the changes in the features or reward functions.
For now, I am using only 4 features to represent the Pacman World:
For now, I am using only 4 features to represent the Pacman World:
- One divided by the distance to the closest dot or power dot.
- One divided by the distance to the closest blind ghost.
- The quantity of ghosts one step away divided by four.
- Whether the Pacman is going to be eaten or not.
Each feature receive a weight by the Qlearning algorithm, usually good things are positive numbers and bad things negative numbers, but I am going to explain more with more details in a further post. The reward function that I am using is based in 5 rewards:
- DOT: value = 5
- POWER_DOT: value = 10;
- EAT_GHOST: value = 800;
- DIE: value = -1200;
- WALK: value = -2;
It is clear that the worst thing that could happen is to die, and the reward function reflect that.
This is a list of some other features that I used in other versions of the game: Eat Dot, Eat Power Dot, Eat a Ghost, Distance to Power Dot, Distance to closest active ghost, Sum of distance of active ghosts divided by the number of ghosts actives (I was believing so much in that one, but it create a Pacman afraid of moving) and etc.
All the code related with the features and rewards can be found in those classes that explain themselves with their names: FeaturesExtration, PacmanFeatures and Reward.
All the code related with the features and rewards can be found in those classes that explain themselves with their names: FeaturesExtration, PacmanFeatures and Reward.
Connectors
The first issue that I faced in this project was "How to represent the Pacman game using LISP", and I couldn't find a solution fast enough to be done right on time at the end of the semester, so I decide to use Java to represent the environment and LISP to control the intelligence of the Pacman, as required in the course. For that I used the Armed Bear Common Lisp Library written in Java that can run Lisp code and make the connection between both.


That is a pretty good library, but I had some hard time trying to give some complex objects to the LISP side of my software, so I decided to transform everything in strings of integer numbers and than parse it back in the format that I wanted on LISP side, I had some problems but in the end I could encapsulate everything in those two classes(LispFunction.java and LispConnection.java) and in the first session of code in lisp.
Wednesday, April 29, 2015
Data from humans
Hi everyone, I am almost done with the Pacman, I begun to collect performance data from the Qlearning and from the random Pacman, but I have to change some things yet. Moreover, I am planning to use data of human performance too, so if you have some time to play one or two rounds would be really nice. You can find the game here, you just have to have Java in your computer, to run the Pacman file and after play, send the content of the directory "Output" to emouragu@oswego.edu. Thank you!
Thursday, April 2, 2015
Monday, February 23, 2015
Scholarship Requires Planning

- Code Refractory and Scratch of Classes Design
- Point of completion: Code refactored and classes design sketch
- Deadline: 4d - 3/1/2015
- Description: Refactor the code of the open source pacman in order to facilitate the development and the understanding of anyone who look at this code, also, a simple UML classes design can guide the next steps of the project.
- Connectors
- Point of completion: java-connection and LispConnection classes working good
- Deadline: 8d - 3/9/2015
- Description: This classes will encapsulate all the communication and changes in data format between the java and lisp programs.
- Feature and Reward Extractor
- Point of completion: FeatureExtractor class and getLastReward() method working good.
- Deadline: 15d - 3/24/2015
- Description: The FeatureExtractor.java class will calculate and provide a list of features in a specific state with a specific action to the QAgent in Lisp. For example, the number of ghosts in 1 step of distance. The method getLastReward() provide the difference in the pacman score after last action.
- Q-Learning Agent
- Point of completion: Q-Learning Algorithm controlling the Pacman.
- Deadline: 15d - 4/8/2015
- Description: This phase is the core of the project, here I am going to implement the Q-Learning Algorithm.
- Game Design Improvement and/or Search Algorithms to Improve Distance Features
- Point of completion: A version with the game design improved
- Deadline: 10d - 4/18/2015
- Description: Search Algorithms to Improve Distance Features in the pacman agent and/or Improve Ghosts AI and/or add new levels in the game and/or new audio or graphic features.
- Statistics
- Point of completion: Complete statistic evaluation comparing the random machine, the human player and the q learning algorithm evolution.
- Deadline: 5d - 4/23/2015
- Description: If the LRT Algorithm is good I will implement some chase and scattering techniques to the ghosts and make the game more interesting, if it is not good, I will see what is wrong and make changes.
- Paper
- Point of completion: Project Paper Complete
- Deadline: 11d - 5/5/2015
- Description: This paper is going to describe all the algorithms used in the project.
Scholarship Requires Context
Jarad Cannon, Kevin Rose, Wheeler Ruml. “Real-Time Motion Planning with Dynamic Obstacles” Proceedings of the Fifth Annual Symposium on Combinatorial Search (2012).
Description: Probably it is going to be the main guide for the project, because this article describe the exact kind of algorithm that I need to use and compare some of them, showing pros and cons of each.
Bulitko, Vadim, Yngvi Björnsson, and Ramon Lawrence. "Case-Based Subgoaling In Real-Time Heuristic Search For Video Game Pathfinding." (2014): arXiv. Web. 22 Feb. 2015.
Description: This article is going to be useful because it talk about subgoaling in the context that I am working with. I could assume each dot in the pacman game as a subgoal.
Maxim Likhachev, David Ferguson , Geoffrey Gordon, Anthony (Tony) Stentz, and Sebastian Thrun, "Anytime Dynamic A*: An Anytime, Replanning Algorithm," Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), June, 2005.
Description: The LRTA* algorithm is based in static obstacles, differently of the pacman game. So, the article describe one variation of this algorithm to deal with this situations.
I. Szita and A. Lorincz (2007) "Learning to Play Using Low-Complexity Rule-Based Policies: Illustrations through Ms. Pac-Man", Volume 30, pages 659-684
Description: This work describe some heuristics and the use of some algorithms in the pacman game.
Korf, R. E. 1990. Real-time heuristic search. Artificial Intelligence 42(2-3):189–211.
Description: This article is a great reference in the real time heuristic search field.
David M. Bond, Niels A. Widger, Wheeler Ruml, Xiaoxun Sun.”Real-Time Search in Dynamic Worlds” Proceedings of the Symposium on Combinatorial Search (SoCS-10), 2010.
Description: This article describe other kind of Real-Time Search in Dynamic Worlds algorithm, the
Garcıa, Adrián Ortega, and Juan Carlos Orendain Canales. "Agent Pac-Man: A Study in A* Search Method." Sistemas Inteligentes: Reportes Finales Ene-May 2014} (2014): 1. http://www.researchgate.net/profile/Gildardo_Sanchez-Ante/publication/262600223_Sistemas_Inteligentes_Reportes_Finales_Ene-May_2014/links/0f317538331511fb40000000.pdf#page=6
Description: This work describe the use of A* search method in the Pacman game and also a different behaivor to the ghosts.Q-Learning Algorithm
Reinforcement Learning to Train Ms. Pac-Man Using Higher-order Action-relative Inputs
Deep Learning for Reinforcement Learning in Pacman
Technical Note Q-Learning
Reinforcement Learning and Function Approximation∗
Q-Learning with Linear Function Approximation
Q-learning with linear function approximation
An Analysis of Reinforcement Learning with Function Approximation
Double Q-learning
Approximate dynamic programming and reinforcement learning∗
Combining Q-Learning with Artificial Neural Networks in an Adaptive Light Seeking Robot
Extra
Course berkley
Lecture
Slides
Books
Wiki
Tutorial
https://docs.google.com/document/d/1j6A34-NBcdTyjQJGvlcyn0tOgucY4wdiQMXj-rlQtzw/edit?usp=sharing
Sunday, February 22, 2015
Wednesday, February 18, 2015
Sunday, February 15, 2015
Concept Proof - Pacman LISP + JAVA
I have been doing some tests to see if the Java and Lisp would really work good together to the project using the library abcl. I had pretty good results, but probably I will have some trouble to convert java arrays in lisp lists and with the old design patterns adopted in the Open Source PACMAN. Although, it is part of the process of learning. This project already has "smart" ghosts that are unable to turn back in the path. I made some changes in the code/design and add one lisp function to control the Pacman. With the human behavior of "lose in a hurry" It is going randomly and also it is not allowed to turn back in the path.
You can find the source code on GitHub and a "Concept proof" video bellow:
You can find the source code on GitHub and a "Concept proof" video bellow:
Wednesday, February 11, 2015
Monday, February 9, 2015
Candidate topics for a Research/Programming Project
Content Based Recommendation System to Events
Choose which bar, show, theater, play or any sort of event, go or do not go can be a big issue for people who live in a big city with a lot of options, or even to people who are visiting a new city. There are some apps, as Foursquare, that could help in this situations, but none of them gives personal recommendation and none of them are based in events. This project would be the creation of a recommendation system to events, where the user could see their prefer kind of events, and a guess about how they would rate those events. In this way, the user would save time, instead of look at all events in the city to choose which one is the best, the user could simply see the top ten events for him. The system would provides personalized recommendation by matching user’s interests with description and attributes of this events. For example, the place, actors, artists, theme, day of week, time kind of music and etc. Moreover, the system would obtain the user’s interests using their likes or dislikes in previous events, their friends interests or even a initial interview. The machine learning would be an essential part of the system, for example, a decision tree could be used to learn a model that smartly chooses minimum set of question while learning user's preference in the initial interview. Moreover, for the recommendation of the event, some standard techniques of machine learning could be used, such as, logistic regression, support vector machines, decision tree or other. Considering the natural interaction required to this system, it should be web based.
Real-Time Learning with Dynamic Obstacles Applied in A PacMan
Real time learning algorithms are commonly used in situations that the agent has to interleaves planning and acting to have a quick answer on a path finding problem. Also, some of those algorithms include obstacles in their analysis, obstacles that can be dynamic or not. It can be used in many different situations, for example a flying drone or a robust robot motion planning in dynamic environments. The project to the course could be the application of some of these algorithms, such as, LSS-LRTA* or neural networks, to a PacMan game.


Articles that can help
http://rvsn.csail.mit.edu/location/Minkov_collaborative_recommendation.pdf http://www.aaai.org/ocs/index.php/SOCS/SOCS12/paper/viewFile/5412/5174 http://www.gamesitb.com/nnpathgraham.pdfhttp://www.gamesitb.com/pathgraham.pdf
Other Ideas
Smart Othello - Reversi GameTraffic Tweet Classifier
Sunday, February 8, 2015
Tic Tac Toe - Visualization, Analysis, and Statistics
In this picture is possible see the "Visualize" method working:
).png)
In this picture is possible see the "Analyze" method working:
).png)
Combining them we can see the method "demo-va" working:
.png)
Bellow, a image of the use of the method "stats" to display the statistics of the game played randomly showing the games.
.png)
Running the algorithm with two random players and 30000 games, we could see the statistic in the view of the first player. The result was: 58.43% of win, 28.74% Lost and 12.82% Draw. As expected for most of class it was about 60% of chance of winning. Bellow you can see a screen shot of the test.
and here the code.
Also, the most interesting part of the code was the method of analysis.
(defmethod analyze((l list))
(defparameter wonlist '( (nw n ne) (w c e) (sw s se) (nw w sw) (n c s) (ne e se) (nw c se) (ne c sw)))
(defparameter result 'd)
(defparameter xlist ())
(defparameter olist ())
(loop
for n from 0
for move in l
if (and (evenp n) (equal result 'd)) do (setf xlist (cons move xlist))
do (loop for lane in wonlist
if (equal (length(intersection xlist lane)) 3)
do (setf result 'w)
)
if (and (oddp n) (equal result 'd)) do (setf olist (cons move olist))
(loop for lane in wonlist
if (equal (length(intersection olist lane)) 3)
do (setf result 'l)
)
)
result
)
Sunday, February 1, 2015
Random Tic Tac Toe
It is a simulation of 5 games in a random tic tac toe:

Impressively, the first player won every game. This is the file of the code.
Wednesday, January 28, 2015
Learning about Learning and Machine Learning
Learning
I liked the funny way that Stephen Marsland described the learning process based in experiences in the book Machine Learning An Algorithmic Perspective. He said: "Learning is what gives us flexibility in our life; the fact that we can adjust and adapt to new circumstances, and learn new tricks, no matter how old a dog we are!"
Machine Learning
From Stephen Marsland in the book Machine Learning An Algorithmic Perspective: "Machine learning, then, is about making computers modify or adapt their actions (whether theses actions are making predictions, or controlling a robot) so that these actions get more accurate, where accuracy is measured by how well the chosen actions reflect the correct ones."

Machine Learning Research Project
Uncovering Social Spammers: Social Honeypots + Machine Learning
Kyumin Lee, James Caverlee and Steve Webb
This is a interesting article, that was wrote in 2010 at Texas A&M University. It explored the use of machine learning to create spam classifiers able to detect new and emerging spam in social networks. Their initial data base to train the classifier was based in social honeypots, bots that analysed spam behavior on the social media. In addition, a human inspected the results of the social honeypots to certify a spam user.
In this image is possible to see theirs system work:

In conclusion, they got 82% of precision on detection of spam users on twitter using the Decorate classifier. This article can be found here.
In this image is possible to see theirs system work:
In conclusion, they got 82% of precision on detection of spam users on twitter using the Decorate classifier. This article can be found here.
Tuesday, January 27, 2015

Subscribe to:
Comments (Atom)