Basic Idea
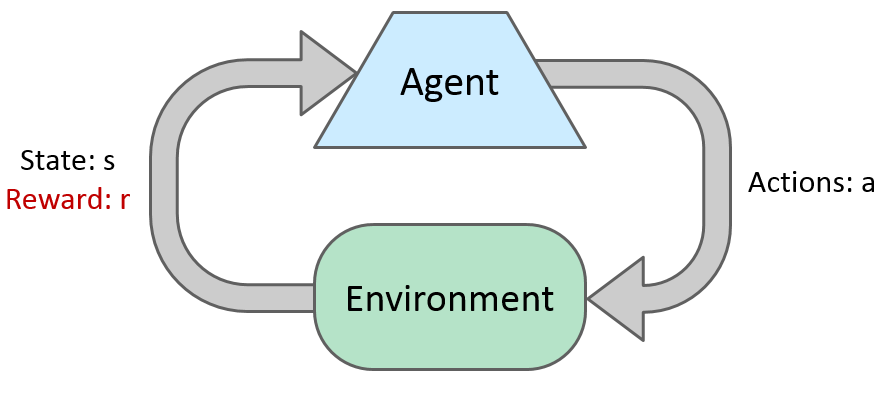
Most algorithms of reinforcement learning follow the model of a MDP, but not knowing T or R.
Markov Decision Process
A set of states s in S
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
No comments:
Post a Comment