
Wednesday, May 6, 2015
Tuesday, May 5, 2015
Statistics
Now I have some data to show and I made some cool graphs. First, I would like to explain the meaning of the terms "Round" and "Try" in my statistics. When someone plays Pacman and die 3 times, it is one round, and his/her first try. If he/she keep playing, without closing the game, it is going to be the second try, and in that way go on. Second, I ran the QLearning Pacman for 4600 rounds, the Random Pacman for 2000 rounds, and 4 different humans played two rounds each. It is a pretty small number of human players, but we can have some general view from that anyway. Lets go to the graphs:
So, when we are playing against each other, the most common question is "What is your high-score?" than, I decided to compare it, and the result was pretty impressive. The Qlearning algorithm achieved a score almost two times higher than the humans.




So, when we are playing against each other, the most common question is "What is your high-score?" than, I decided to compare it, and the result was pretty impressive. The Qlearning algorithm achieved a score almost two times higher than the humans.
Someone could say: "Okay, but I am sure that humans gonna have a better average!", but the data shows the opposite. Even with a smaller difference, the Qlearning algorithm still showing a better score.
At first, I thought that I could see the evolution of the Pacman through his tries, so I build that graph bellow that shows the average of scores through his tries. Otherwise, the results showed that the learning of the algorithm is so fast, that it is not really visible through tries, because it happen just in the first moment of each experience. In this chart I decided to use a average of all human scores to be seen as a reference of performance.
QLearning Pacman is better than humans?
I wouldn't say that, besides the fact that we have a really small population of human rounds, the way that I designed the game can influence in the final result of that data. I designed the game to increase the difficulty exponentially through the levels intended in make the game quick, interesting and challenger. As we can see in the graph bellow, the humans has a tendency to try go on through levels faster that the QL Pacman. It happens because I gave a high reward to the QL Pacman when he ate ghosts, so he decided to give priority to that instead of only go to the next level. Otherwise, it doesn't mean that the humans use a bad strategy, the key point here is that the level 2 (which is the third) is really hard and no one could get through it.
Q-Learning Pacman
The main goal of the project is to apply the QLeaning algorithm in the Pacman, so I am going to explain how that algorithm works.
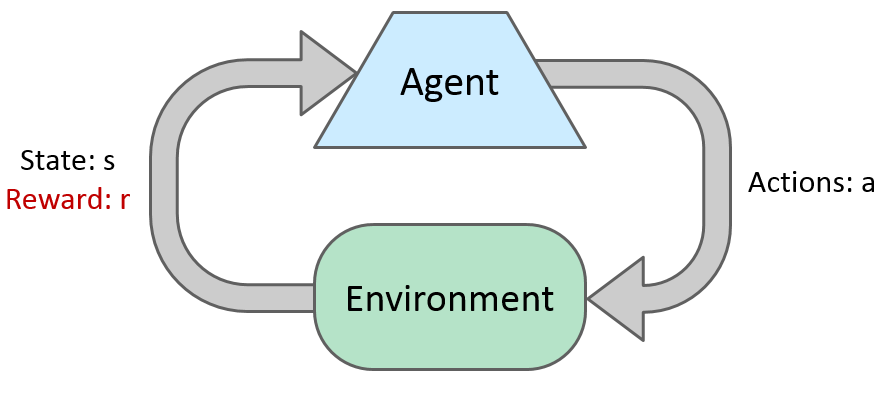
Basic Idea
Most algorithms of reinforcement learning follow the model of a MDP, but not knowing T or R.
Markov Decision Process
A set of states s in S
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
A set of actions (per state) A
A model T(s,a,s’) ; P(s'|s,a)
A reward function R(s,a,s’)
A policy Pi(s)
Here you can see a set of good explanations of MDP from Georgia Tech.
Most theory behind the Qlearning algorithm I leaned with the material of the course CS188 Intro to AI from UC Berkeley. You can find all lectures and really good stuff in their channel on Youtube, such as this video bellow. Also, the book Artificial Intelligence: A Modern Approach from Stuart J. Russell and Peter Norvig is a excellent source. If you are interested only in the QLeaning algorithm and Reiforcement Leaning you can see the lecture 10 (bellow) and the lecture 11.
Now that we have a background in the Qlearning and that we know our Features that represent a State and our Reward function, the only thing to do is define the variables.
Epsilon - Exploration rate - I decided to keep 0 because there isn't much things to the Pacman try, basiclly you eat dots, power dots, ghosts and die. He can do it without a exploration function only taking random decisions when doesn't know what to do.
Gamma - Discount factor - Tell how important are the future step to the leaning, in our case I left it 0.01 because it really doesn't matter in our game.
Alpha - Learning rate - this is the most important variable to check, it tells how much the Pacman should learn from each episode and it make the knowledge convey or not. In our case it was 0.01 for the firsts 1500 requests of actions to take, and then 0.0001.
This code can be found here.
Monday, May 4, 2015
Features and Rewards
The features and the rewards are the soul of the QLearning algorithm and of the Pacman agent. Nonetheless, it is the hardest part to get right and, even with high scores, I still thinking the best way to do. I implemented up to 10 different features to represent a state, and tried a lot of combinations between then, but I could do it for more one month until discover the best way, because it is really fun to see the variations in the Pacman behavior according with the changes in the features or reward functions.
For now, I am using only 4 features to represent the Pacman World:
For now, I am using only 4 features to represent the Pacman World:
- One divided by the distance to the closest dot or power dot.
- One divided by the distance to the closest blind ghost.
- The quantity of ghosts one step away divided by four.
- Whether the Pacman is going to be eaten or not.
Each feature receive a weight by the Qlearning algorithm, usually good things are positive numbers and bad things negative numbers, but I am going to explain more with more details in a further post. The reward function that I am using is based in 5 rewards:
- DOT: value = 5
- POWER_DOT: value = 10;
- EAT_GHOST: value = 800;
- DIE: value = -1200;
- WALK: value = -2;
It is clear that the worst thing that could happen is to die, and the reward function reflect that.
This is a list of some other features that I used in other versions of the game: Eat Dot, Eat Power Dot, Eat a Ghost, Distance to Power Dot, Distance to closest active ghost, Sum of distance of active ghosts divided by the number of ghosts actives (I was believing so much in that one, but it create a Pacman afraid of moving) and etc.
All the code related with the features and rewards can be found in those classes that explain themselves with their names: FeaturesExtration, PacmanFeatures and Reward.
All the code related with the features and rewards can be found in those classes that explain themselves with their names: FeaturesExtration, PacmanFeatures and Reward.
Connectors
The first issue that I faced in this project was "How to represent the Pacman game using LISP", and I couldn't find a solution fast enough to be done right on time at the end of the semester, so I decide to use Java to represent the environment and LISP to control the intelligence of the Pacman, as required in the course. For that I used the Armed Bear Common Lisp Library written in Java that can run Lisp code and make the connection between both.


That is a pretty good library, but I had some hard time trying to give some complex objects to the LISP side of my software, so I decided to transform everything in strings of integer numbers and than parse it back in the format that I wanted on LISP side, I had some problems but in the end I could encapsulate everything in those two classes(LispFunction.java and LispConnection.java) and in the first session of code in lisp.
Subscribe to:
Comments (Atom)